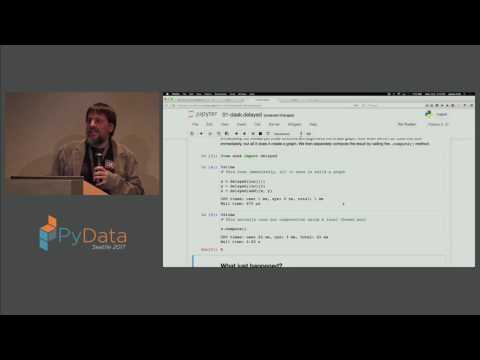
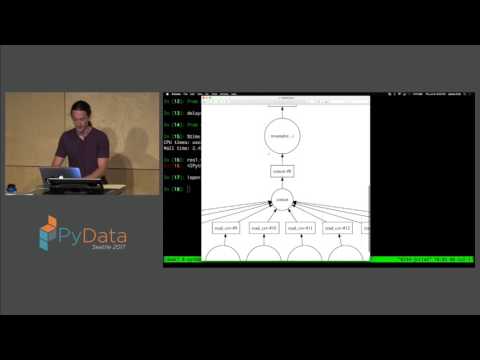
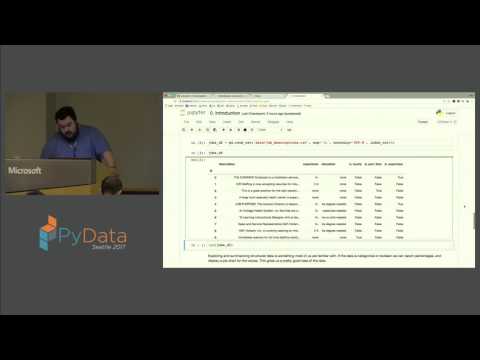
44:33 Applying the four step "Embed, Encode, Attend, Predict" framework to predict document similarity PyData
26:01 Katie Porterfield - BrainDrain Using Machine Learning and Brain Waves to Detect Errors in Human PyData
29:26 Keira Zhou - Batch and Streaming Processing in the World of Data Engineering and Data Science PyData
37:14 Raj Singh - PixieDust make Jupyter Notebooks with Apache Spark Faster, Flexible, and Easier to use PyData
1:56:02 Denny Lee, Tomasz Drabas - A Quick Primer on TensorFrames: Apache Spark and TensorFlow Together PyData
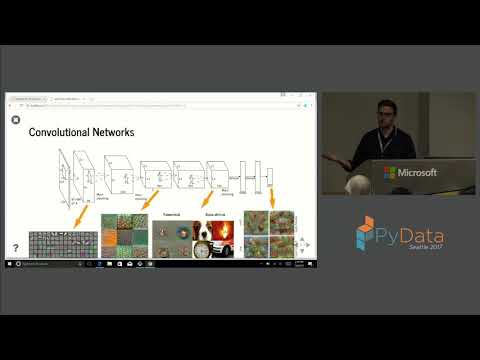
37:14 Kyle Shaffer - Code First, Math Later: Learning Neural Nets Through Implementation and Examples PyData
35:46 Claire Kelley, Sarah Kelley - Automatic Citation generation with Natural Language Processing PyData
19:43 Unlocking the power of AI: A fundamentally different approach to building intelligent systems PyData
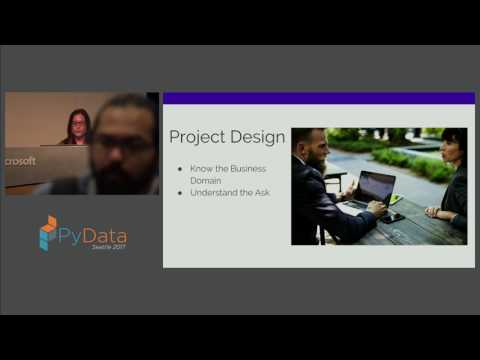
34:09 Saranga Komanduri, Lori Eich - Moving notebooks into the cloud: challenges and lessons learned PyData
53:46 PyData Seattle Diversity Panel - How diversity drives excellence in our data driven tech world PyData